

Antes de meternos en harina y explicar lo que son y cómo funcionan las cabeceras HTTP, vamos a dar una breve introducción de lo que es el protocolo HTTP en sí, y cómo funciona.
Qué es el protocolo HTTP y cómo funciona
Seguramente, alguna vez te has fijado en la barra del navegador y te has preguntado por qué todas direcciones empiezan por “https://” o “http://”. Esto es porque todo “Internet” o mejor dicho la World Wide Web funciona bajo el protocolo HTTP o “Hyper Text Transfer Protocol”.
Este protocolo es el que se utiliza al pedir la mayoría de recursos utilizados por las páginas web. Por lo que la comunicación entre el cliente y el servidor a la hora de pedir por ejemplo una imagen, se realiza a través de HTTP. Cada una de estas peticiones son enviadas a un servidor, el cual recibirá, tratará y devolverá de nuevo al cliente.
Fue diseñado a principios de la década de 1990. Aunque la base de lo que tenemos ahora sigue siendo la misma, ha sufrido numerosas modificaciones y mejoras a lo largo del tiempo. La RFC de HTTP/1.1 se recoge en la rfc2616.

Qué son las cabeceras HTTP
Una vez “explicado” cómo funciona el protocolo HTTP, vamos a pasar a explicar qué son y cómo funcionan las cabeceras.
Cuando realizamos una petición a un servidor (para hacerlo bastará simplemente con acceder a una url desde nuestro navegador), dicha petición (tanto la petición del cliente como la respuesta del servidor), son enviadas con una serie de “metadatos”. Estos metadatos son las llamadas cabeceras HTTP. Las cabeceras HTTP son un elemento imprescindible en la comunicación HTTP ya que nos van a proporcionar información acerca del cliente que envía la petición, el servidor, la web solicitada, etc.
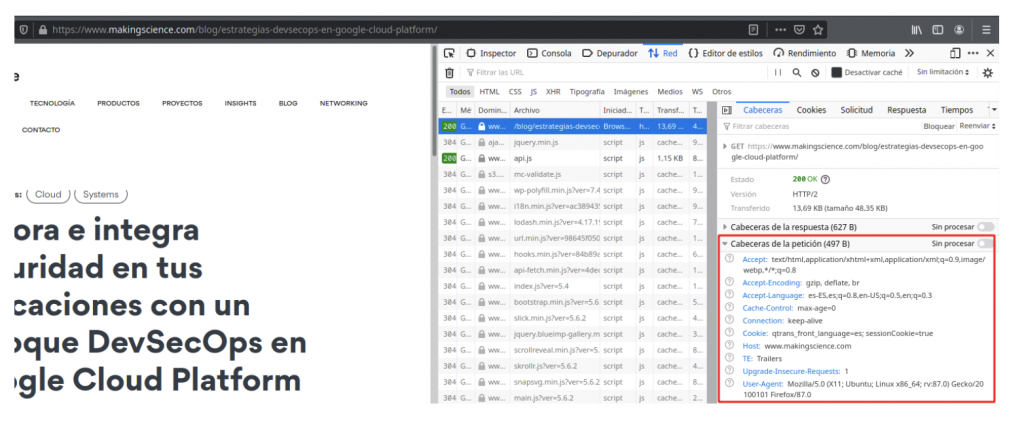
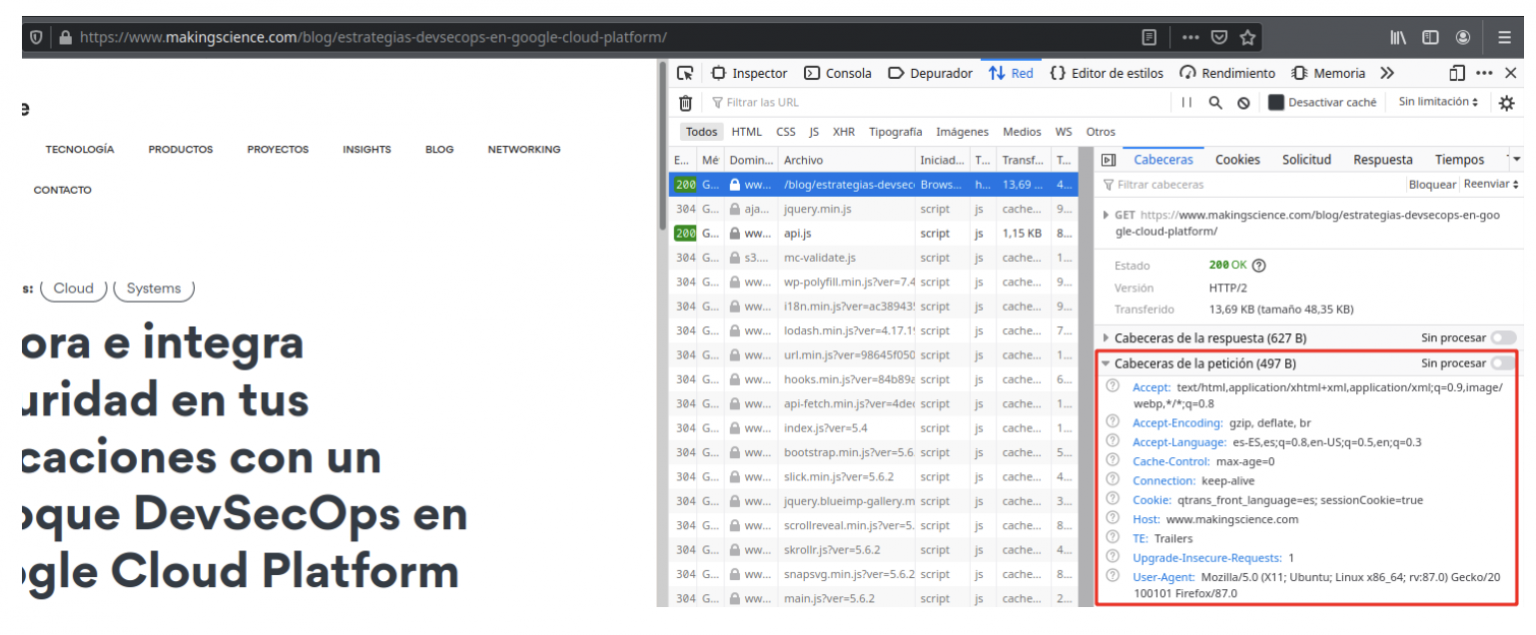
Pero, ¿por qué nosotros no vemos toda esa información? Cuando entramos en una web a través del navegador y nos movemos por ella, no vemos este tipo de información ya que para visitar una web, leer una noticia o ver un video esta información nos es irrelevante. Pero por debajo se está estableciendo una comunicación entre nuestro cliente y el servidor en la que se están enviando y recibiendo estos metadatos. Esto lo podemos ver echando un vistazo a las peticiones que hemos realizado al servidor.
(No te preocupes si no sabes ver las cabeceras desde el navegador. Más adelante se explica cómo sacar las cabeceras desde consola y el navegador).
Muchas cabeceras son compartidas, es decir, se utilizan tanto en la solicitud que se haga del recurso como en la respuesta de petición que nos de el servidor. Es necesario puntualizar y tener en cuenta que no siempre es así, y habrá cabeceras como por ejemplo la cabecera “Location” que solo se utiliza la respuesta del servidor.
No te preocupes si ahora mismo no entiendes nada de lo que indican las cabeceras, a continuación te explicamos algunas de las cabeceras más comunes y la información que contienen.
Tipos principales de cabeceras
Hay multitud de cabeceras con información diferente. A continuación se van detallar algunas de las más comunes y que nos pueden proporcionar información útil:
AlgunaS de las cabeceras HTTP más comunes:
-
- Host: indica el nombre del dominio.
- Age: indica cuantos segundos lleva cacheado el objeto/recurso en un servidor proxy intermedio.
- Cache-control: Cuánto tiempo puede estar un objeto en caché. El tiempo viene expresado en segundos.
- Content-Encoding: indica qué codificación de contenido se aplica en el recurso.
- Location: Indica la url destino en caso de redirección.
- Set-Cookie: Indica la cookie establecida en el cliente.
- Server: Información sobre el servidor que responde nuestra petición.
- Status: Código de respuesta de la petición.
- User-Agent: Indica la herramienta desde la cual se ha realizado la petición.
- Vary: Indica los valores y cabeceras que han de tenerse en cuenta a la hora de generar/solicitar un archivo desde la caché.
Cabeceras personalizadas
Hasta ahora hemos visto algunas de las cabeceras más comunes pero ¿y si quiero añadir una cabeceras personalizada?. Las cabeceras personalizadas son una herramienta muy útil a la hora de transmitir información, detectar problemas o añadir nuevas funcionalidades. Por ejemplo, estas cabeceras son un recurso muy utilizado por las CDN, ah ¿que todavía no sabes lo que es una CDN? Te lo explicamos en una de nuestras últimas entradas.
Hasta hace poco, el “estándar” era nombrar las cabeceras personalizadas con el prefijo “X-” pero desde Junio de 2012, esta nomenclatura ha quedado obsoleta, este cambio lo podemos encontrar en la rfc6648. La razón de dicho cambio fue porque muchas de las cabeceras personalizadas se empezaron a estandarizar. Esto dio lugar a un problema y es que al estandarizar estas cabeceras los navegadores debían de soportar tanto la cabecera estandarizada (sin prefijo) como la que utilizaba el prefijo, o los sistemas que utilizaban dichas cabeceras con prefijo debían de actualizarse.
Aunque las cabeceras que utilizan el prefijo se siguen utilizando. A la hora de implementar nuevas cabeceras personalizadas deberíamos de elegir un nombre representativo, que no utilice el prefijo.
Os dejamos por aquí algunas de las cabeceras personalizadas que se utilizan:
- X-Powered-By: Identifica el software o servidor. Muy común en instalaciones de WordPress.
- X-Forwarded-For: Identifica la IP de un cliente, cuya conexión se ha realizado a través de un proxy.
- X-Forwarded-Proto: Identifica el protocolo de conexión de un cliente, cuya conexión se ha realizado a través de un proxy.
- X-Forwarded-Host: Identifica la cabecera Host original de una petición, cuya conexión se ha realizado a través de un proxy.
Cómo ver las cabeceras
Vamos a explicar cómo ver las cabeceras HTTP desde dos herramientas distintas:
Consola: Para listar las cabeceras HTTP de una url por consola podemos utilizar la herramienta curl. Simplemente habrá que lanzar desde consola el siguiente comando:
Lo que estamos haciendo es pasarle el parámetro “-I” a la herramienta curl. Esto lo que indica, es que únicamente nos muestre las cabeceras.
HTTP/2 200
server: nginx
date: Mon, 12 Apr 2021 11:33:34 GMT
content-type: text/html; charset=UTF-8
vary: Accept-Encoding
set-cookie: qtrans_front_language=es; expires=Tue, 12-Apr-2022 11:33:34 GMT; Max-Age=31536000; path=/blog/
link: <https://www.makingscience.com/blog/wp-json/>; rel=»https://api.w.org/»
link: <https://www.makingscience.com/blog/wp-json/wp/v2/posts/4307>; rel=»alternate»; type=»application/json»
link: <https://www.makingscience.com/blog/?p=4307>; rel=shortlink
access-control-allow-origin: *
access-control-allow-headers: *
via: 1.1 google
alt-svc: clear
Navegador: Para ver las peticiones desde el navegador, vamos a darle a click derecho encima de la web y pinchamos en la opción “Inspeccionar elemento”. Esto nos abrirá un nuevo apartado en la web donde encontramos una pestaña que indica “Red”, es ahí donde veremos todas nuestras peticiones realizadas. Al entrar en cualquiera de las peticiones realizadas podremos ver las cabeceras.




 Configuración de cookies
Configuración de cookies