

¿En qué consiste la visualización de datos?
La visualización de datos lo que intenta hacer es aprovechar nuestra enorme capacidad de analítica visual, para hacer accesibles esas relaciones, esa información, de esos conjuntos de datos abstractos a nuestro entendimiento. En la visualización de datos básicamente lo que hacemos es codificar o traducir a un lenguaje visual, a un lenguaje entendible por nuestra cognición, por nuestra mente, toda esa información.
Yusef Hassan
La visualización de datos se impulsa por su capacidad de revelar las historias que se esconden dentro de los datos.
Edward Segel and Jeffrey Heer
Ya por la segunda mitad del siglo XX John Tukey presentó el poder de la visualización de datos como un medio para explorar y dar sentido a los datos cuantitativos y a este enfoque estadístico lo llamó análisis exploratorio de datos (Exploratory Data Analysis). Años después, hacia la década de los años 80, Edward Tufte comenzó a mostrar otras formas efectivas de mostrar datos visualmente, reflejándolo en su libro “The visual display of quantitative information”. Todo ello favoreció la aparición de una nueva especialidad académica acuñada como “Information visualization”, que gracias al trabajo de académicos como Jock Mackinlay y Ben Shneiderman, entre otros, permitieron traspasar los muros académicos y llegar hacia el mundo profesional. En la actualidad, la disciplina de la visualización de datos ha ido evolucionando a la par que el desarrollo de la tecnología va en aumento. Permitiendo la recopilación de gran cantidad de información cuantitativa, y ha sido la consiguiente necesidad de mostrarla, lo que ha impulsado el desarrollo de herramientas como fueron las hojas de cálculo, las cuales constituyeron una revolución dentro de la informática personal, al acercar al usuario doméstico todo el potencial de cálculo de datos, reservado desde sus comienzos a un uso más empresarial. Un viaje que comenzó por 1979 con el desarrollo de la primera gran aplicación que popularizó las hojas de cálculo en los ordenadores llamada VisiCal, pasando por Lotus 1-2-3 hasta llegar a la tan conocida y usada Excel. En la actualidad, las hojas de cálculo digitales siguen en apogeo y evolucionando, impulsadas por nuevas alternativas como Google Sheets ofreciendo al mercado nuevas capacidades. Esta revolución que hemos experimentado con el desarrollo de este tipo de software (poniendo el foco en las últimas décadas hasta la actualidad), han sido las causantes de que seamos tan malos diseñando gráficas y que mucho de lo que nos encontramos sea considerado como «basura gráfica». Son estas aplicaciones que al estar tan mal diseñadas nos han hecho a toda la población en general malos comunicando información cuantitativa.
Yusef Hassan
Estas herramientas tienen un problema. Propician un uso incorrecto a la hora de representar datos, mostrando una serie de opciones que permiten a los usuarios seleccionar un tipo concreto de gráfica para representar los datos. El problema de estas herramientas ya no es que las opciones por defecto que nos muestran estén mal, si no que se basan en un modelo erróneo de representar datos al dar la opción de “seleccionar tipo de gráfica”. Esta opción nos obliga a encajar los datos que necesitamos representar en una serie de gráficas preestablecidas que nos ofrece la propia herramienta y esto, es un error.
¿Por qué?
Porque la selección de un tipo de gráfica u otro ha de contemplar para empezar un análisis previo de los propios datos. Este modelo, en el cual una de las primeras decisiones que debemos tomar es seleccionar el tipo de gráfica, nos obliga a encajar nuestros datos en un tipo de gráfica visual concreta seleccionada previamente. La representación de datos persigue una serie de objetivos, entre las que destacan:
- Transmitir y comunicar un mensaje.
- Presentar grandes cantidades de información de forma concisa, compacta y entendible.
- Revelar datos, al mostrar las relaciones causa-efecto, revelando las relaciones que a priori no son evidentes.
- Controlar la evolución de parámetros de forma periódica
¿Existe otra forma de representar datos que no sea el modelo “seleccione tipo de gráfica”?
A finales de los años 90 Leland Wilkinson publicó “The Grammar of Graphics”, venía a decir que en el lenguaje visual existe una gramática, unas reglas sintácticas y semánticas (así como la gramática nos ofrece la habilidad de construir oraciones combinando y organizando distintos elementos del lenguaje, la gramática de gráficos nos ofrece elementos básicos para crear gráficos) y cuando estamos visualizando datos lo que estamos haciendo no es seleccionar un tipo de gráfica sino crear un expresión gráfica propia. En esencia, una gramática de gráficos es un marco que nos permite describir concisamente los componentes de cualquier gráfico. Lo que debemos hacer es asociar cada una de las variables que conforman el dataset a atributos gráficos concretos, es decir, determinar de qué forma se van a representar cada una de esas variables. En función del tipo de variables, unos atributos gráficos funcionan mejor que otros.
Un problema de diseño
Cuando lo bonito pasa a ser inútil. 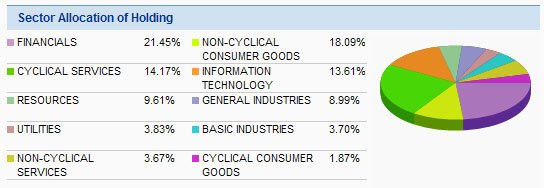 La siguiente gráfica representa las tendencias de diferentes activos por sector. En el lado izquierdo viene descrita la leyenda, asociada a la representación circular tipo “tarta” de la derecha. La tabla se utiliza para buscar los porcentajes de las asignaciones del sector. El principal problema aquí, viene por la representación del gráfico circular. Para que esta representación nos fuese realmente útil debería permitirnos ver rápidamente el desglose de cada uno de los sectores. Sin embargo, para comprender qué representa cada sector debemos mirar la tabla, por lo que se identifican varios problemas: 1- Requiere hacer un trabajo innecesario al obligarnos a mirar de un lado a otro para tratar de comprender qué rebanadas pertenecen a qué sector. 2- Al tener que buscar cada rebanada (sector del gráfico circular) en la tabla de todos modos, el gráfico circular es totalmente prescindible. 3- Los datos que aparecen en la tabla quedan erróneamente representados. El segmento de “cyclical services” parece tener casi el doble de tamaño que el segmento de “Non cyclical consumer goods”. Sin embargo, los valores de la tabla indican que el segmento “Non cyclical consumer googs” es de 18,09% mientras que el otro segmento es solo 14,17%. Estas manipulaciones podrían hacer que se tomasen decisiones mal informados. 4- Otro problema identificado, un poco menos obvio, es que la suma de las partes no da 100%. Cuando se agregan todos los porcentajes de cada uno de los segmentos se obtiene el 98,99%. Solución
La siguiente gráfica representa las tendencias de diferentes activos por sector. En el lado izquierdo viene descrita la leyenda, asociada a la representación circular tipo “tarta” de la derecha. La tabla se utiliza para buscar los porcentajes de las asignaciones del sector. El principal problema aquí, viene por la representación del gráfico circular. Para que esta representación nos fuese realmente útil debería permitirnos ver rápidamente el desglose de cada uno de los sectores. Sin embargo, para comprender qué representa cada sector debemos mirar la tabla, por lo que se identifican varios problemas: 1- Requiere hacer un trabajo innecesario al obligarnos a mirar de un lado a otro para tratar de comprender qué rebanadas pertenecen a qué sector. 2- Al tener que buscar cada rebanada (sector del gráfico circular) en la tabla de todos modos, el gráfico circular es totalmente prescindible. 3- Los datos que aparecen en la tabla quedan erróneamente representados. El segmento de “cyclical services” parece tener casi el doble de tamaño que el segmento de “Non cyclical consumer goods”. Sin embargo, los valores de la tabla indican que el segmento “Non cyclical consumer googs” es de 18,09% mientras que el otro segmento es solo 14,17%. Estas manipulaciones podrían hacer que se tomasen decisiones mal informados. 4- Otro problema identificado, un poco menos obvio, es que la suma de las partes no da 100%. Cuando se agregan todos los porcentajes de cada uno de los segmentos se obtiene el 98,99%. Solución 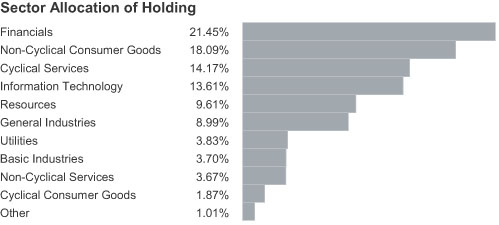 Este diseño simple muestra todos los sectores y sus porcentajes asociados a través de una tabla ordenada. Nos permite asociar fácilmente las barras correspondientes con el porcentaje de cada sector el objetivo de las barras no es discernir valores individuales. Por el contrario, se proporciona un medio para poder comparar rápidamente las magnitudes relativas a cada uno de los valores y extraer anomalías, en el caso de que las hubiese.
Este diseño simple muestra todos los sectores y sus porcentajes asociados a través de una tabla ordenada. Nos permite asociar fácilmente las barras correspondientes con el porcentaje de cada sector el objetivo de las barras no es discernir valores individuales. Por el contrario, se proporciona un medio para poder comparar rápidamente las magnitudes relativas a cada uno de los valores y extraer anomalías, en el caso de que las hubiese.
Representación de datos interactiva
En esta representación se hace hincapié el poder de la representación gráfica de datos como medio manipulatorio, al alterar la percepción visual en función de los datos representados. En este gráfico se equipara el área de terreno con los votos (demócratas vs republicanos), lo que hace es centrar el foco visual en los condados que son grandes a pesar de que no viven muchas personas en ellos. Esos condados rojos de Montana, Dakota del Norte, Dakota del Sur y Wyoming, albergan 1,6 millones de votantes, menos de la mitad del número de votantes que en el condado de Los Ángeles. 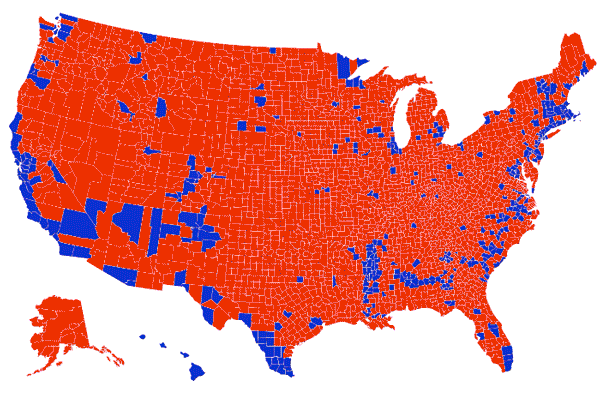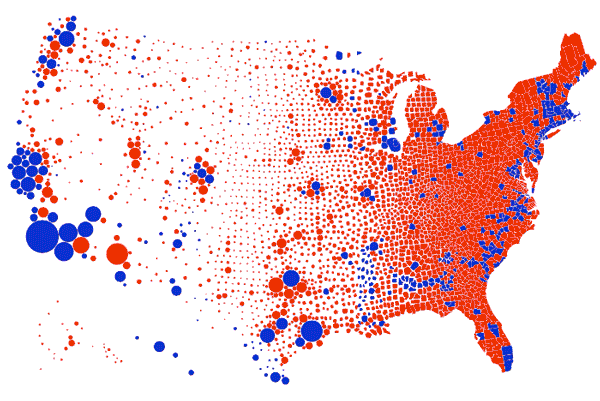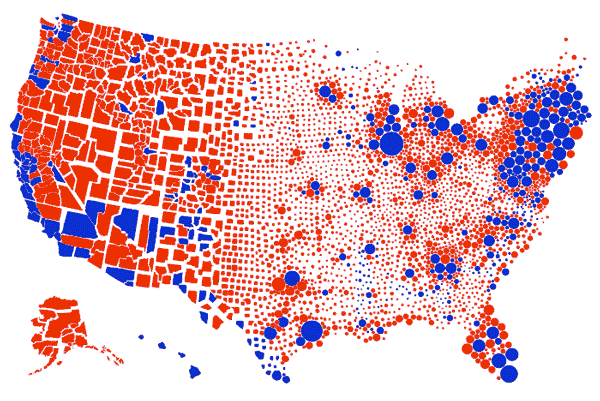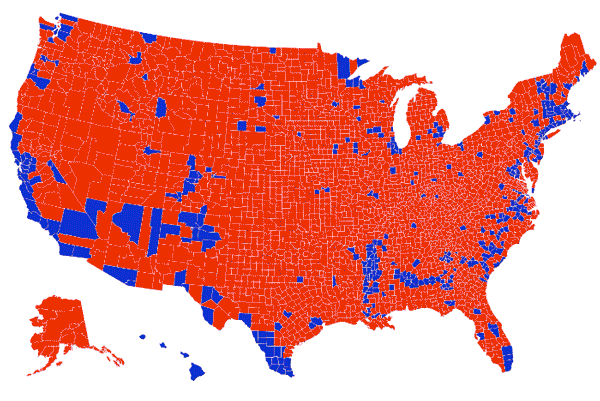




 Configuración de cookies
Configuración de cookies