

Dos familias de algoritmos de recomendación
Los algoritmos de machine learning para realizar recomendaciones suelen dividirse comúnmente en dos categorías:
- Content-based
Como su nombre indica, se basan en las propiedades o atributos de los ítems presentes en el catálogo. Considerando un ítem particular, primero se calcula la similitud de cada uno de sus atributos con cada uno de los atributos de los otros ítems disponibles, y después se decide, asociando un peso, la importancia relativa de cada similitud particular frente a la global (si estoy buscando ordenadores, ¿qué es más importante? ¿Que el precio sea parecido? ¿La memoria? ¿La velocidad del procesador?). Una vez hemos precalculado qué ítems son parecidos entre sí, podemos ofrecer recomendaciones asociadas a un ítem en particular sin necesidad de saber qué está haciendo o viendo el resto de usuarios; es por ello que este tipo de algoritmos son ideales para casos en los que no disponemos de un histórico de interacciones del ítem con múltiples usuarios, ya sea porque el servicio acaba de ser puesto en producción, porque ciertos ítems acaban de ser publicados, o porque hay poco tráfico. Si el usuario no está interactuando con ningún ítem en particular, también podemos activar este algoritmo usando su histórico de interacciones con otros ítems, estimando o promediando qué tipo de características le interesan más de un ítem en general, y recomendando en base a esa estimación, de la misma forma que usamos los atributos de un ítem particular para recomendar ítems asociados.
- Filtro colaborativo
Estos algoritmos, a diferencia de los de tipo content-based, se basan en los datos disponibles de las interacciones de los usuarios con los ítems del catálogo. Estas interacciones pueden ser de dos tipos: implícitas o explícitas. Una interacción implícita sería, por ejemplo, que el usuario hubiese hecho scroll hasta el final de la página de descripción de un ítem, o que hubiese visto más de la mitad de un video que se le ha mostrado. Una explícita, que el usuario hubiese valorado activamente un producto, como dándole al botón del like o dejando una valoración con una puntuación. Estos algoritmos suelen ser más eficientes que los de tipo content-based, ya que son los propios usuarios los que de manera indirecta están recomendando a otros usuarios, adaptándose a las modas e interpretando las características de los ítems como sólo un humano puede hacerlo (¡de momento!). El único problema que tienen es que hace falta una cantidad mínima de tráfico para cada ítem para que las recomendaciones tengan sentido; es por este motivo que este tipo de algoritmos suelen complementarse con otros de tipo content-based para compensar estos “arranques fríos” sin interacciones. Dentro de esta categoría de algoritmos de filtro colaborativo, dos de los que mejor funcionan son: i) Factorización de matrices: Es un modelo basado en la factorización de la matriz de interacciones items-usuarios. Esta factorización produce unas variables ocultas (o latentes), con las cuales se pueden codificar al mismo tiempo los meta-atributos de los ítems disponibles en el catálogo, y las preferencias de los usuarios hacia dichos meta-atributos. Una vez hemos realizado esta factorización, sólo tenemos que cruzar ambas matrices para poder ofrecer recomendaciones personalizadas. Un ejemplo de algoritmo basado en la factorización de matrices es Implicit (que permite ofrecer recomendaciones incluso a usuarios nuevos o anónimos), o el incluido en la librería Faiss (usada por Facebook). 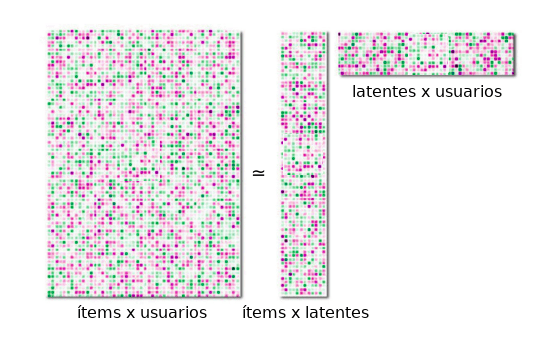 Una matriz de interacciones entre usuarios e ítems (izquierda) se puede descomponer en la combinación de una matriz que codifica los atributos de cada ítem con una serie de valores latentes (medio), y una matriz que codifica las afinidades de cada usuario con dichos valores latentes (derecha). ii) Nearest neighbors (NN): Recomienda ítems que el usuario no ha visto todavía, pero que otros usuarios con gustos parecidos han visto. Este tipo de algoritmos funcionan mejor cuando hay muchos ítems disponibles, y son perfectos para ayudar al usuario a descubrir ítems nuevos y a explorar el catálogo disponible. Algunos ejemplos de algoritmos de tipo NN son Annoy (usado por Spotify) o el incluido en la librería Non-Metric Space Library (NMSLIB).
Una matriz de interacciones entre usuarios e ítems (izquierda) se puede descomponer en la combinación de una matriz que codifica los atributos de cada ítem con una serie de valores latentes (medio), y una matriz que codifica las afinidades de cada usuario con dichos valores latentes (derecha). ii) Nearest neighbors (NN): Recomienda ítems que el usuario no ha visto todavía, pero que otros usuarios con gustos parecidos han visto. Este tipo de algoritmos funcionan mejor cuando hay muchos ítems disponibles, y son perfectos para ayudar al usuario a descubrir ítems nuevos y a explorar el catálogo disponible. Algunos ejemplos de algoritmos de tipo NN son Annoy (usado por Spotify) o el incluido en la librería Non-Metric Space Library (NMSLIB).
- (Extra) Algoritmos híbridos y de Deep Learning:
i) Algoritmos híbridos: Son algoritmos que simplemente combinan los algoritmos content-based y de filtro colaborativo para que se complementen entre sí. Esto se consigue a través de un peso que determina la importancia que cada uno de ellos debe de tener en función de la calidad de las recomendaciones que ofrecen, que dependerá en general de los datos disponibles. El algoritmo de Netflix se encuentra entre los de este tipo. ii) Deep Learning: Este tipo de algoritmos codifican los atributos de cada ítem del catálogo empleando redes neuronales profundas, de una forma parecida a como lo haría el algoritmo de factorización de matrices, pero sin necesidad de depender exclusivamente de interacciones. Son algoritmos bastante más complejos y específicos que los anteriores, y merecerían un post propio para describirlos por encima. Por poner un ejemplo, YouTube utiliza este tipo de algoritmos para recomendar otros vídeos a los usuarios.
Conoce tus datos y elige el algoritmo adecuado
Para elegir nuestro algoritmo, en el fondo lo que tenemos que conocer son los datos de los que disponemos:
- El catálogo de ítems a recomendar
Si en nuestro catálogo disponemos de muchos atributos técnicos con los cuales podemos comparar de una manera analítica los ítems entre sí, como por ejemplo teléfonos móviles o inmuebles, funcionaría bien un algoritmo de tipo content-based para generar recomendaciones, que podría complementarse con uno de filtro colaborativo si el tráfico de usuarios es suficientemente elevado. Si por el contrario nuestro catálogo se compone de ítems menos cuantificables, como canciones o películas, no tenemos muchos atributos para comparar más allá del estilo musical o el género, que a menudo es irrelevante a la hora de hacer comparaciones, y por lo tanto habría que emplear necesariamente un algoritmo de filtro colaborativo.
- El tráfico y las interacciones de los usuarios
Si nuestro servicio tiene mucho tráfico, lo ideal sería usar un algoritmo tipo factorización de matrices usando las valoraciones explícitas de los usuarios si las hay (en cuyo caso disponemos de una fuente valiosísima de información para generar recomendaciones), o un nearest neighbors si el catálogo es muy grande. En cambio, si acabamos de lanzar el servicio o introducimos items nuevos en el catálogo, tendremos que o bien recurrir a un algoritmo tipo content-based (si el tipo de ítem lo permite), o bien recolectar datos durante un tiempo para poder usar de manera eficiente el histórico de interacciones usuario-ítem en el futuro con un algoritmo de filtro colaborativo.
Vigila tus algoritmos
Hay que tener en cuenta que aunque los modelos de machine learning suelen funcionar muy bien, también pueden producir resultados indeseados que conviene filtrar ad hoc. Aquí entran en juego consideraciones varias, como la imagen de marca que se quiere proyectar, o si queremos primar la felicidad o fidelidad de los usuarios frente al volumen de ventas. Por ejemplo, para un portal de noticias: ¿prefiero evitar que, aunque suelan ser populares, se recomienden noticias amarillistas por encima de noticias de contrastada calidad? O si tengo un eCommerce: ¿prefiero que se recomienden productos bien valorados antes que otros productos menos fiables pero que quizás se venden mejor?
Evaluación del recomendador
Por último, conviene considerar cuál es el objetivo del recomendador: ¿quiero recomendar al usuario lo que creo que más le puede interesar, o que descubra ítems que no hubiese conocido de otra manera? ¿Quiero que los usuarios pasen más tiempo en la página? ¿Quiero que se recomienden ítems de todo el catálogo y no sólo los más populares? Para analizar la consecución de estos objetivos, suelen utilizarse algunas métricas comunes, como por ejemplo:
- CTR (Click Through Rate): El número total de clicks en recomendaciones frente al número total de recomendaciones ofrecidas.
- Recall: Es la “precisión” con la que el recomendador ofrece recomendaciones relevantes. Si tengo un histórico de interacciones de los usuarios con los ítems del catálogo, puedo dividir este set en un subset “de entrenamiento” (interacciones iniciales) y un subset “test” (interacciones posteriores), y calcular recomendaciones usando el primero y ver si éstas eran adecuadas usando el segundo.
- Cobertura: Es el porcentaje de ítems presentes en el catálogo que el sistema de recomendación es capaz de recomendar.
- Personalización: Define la similitud entre las recomendaciones ofrecidas a distintos usuarios. Si esta similitud es baja, significa que el recomendador está ofreciendo una experiencia personalizada a cada usuario.
Una vez puesto en producción, la mejor forma de optimizar el sistema de recomendación, teniendo en cuenta estas métricas y otras, es mediante tests A/B que ofrezcan algoritmos con parámetros o características diferentes, e ir iterando hasta obtener el mejor resultado posible.




 Configuración de cookies
Configuración de cookies